Following the air on GPUs
A team of researchers led by Katherine Osterried (C2SM) and Stefan Rüdisühli (Atmospheric Circulation Group) participated in the CSCS GPU Hackathon with the COSMO online parcel trajectory module. They succesfully migrated the code to GPUs and thereby reduced the computation time on PizDaint by a factor of 30. This speed-up is an important prerequisite to enable high-resolution Lagrangian studies of, for example cloud-circulation interactions or Alpine valley flows, on climatological time scales.

Whether we want to better understand the transport of dust from the Sahara across the North Atlantic, study the complex flow in narrow Alpine valleys or identify the moisture sources that contribute to heavy precipitation, following the path of the air through the atmosphere enables new and exciting process understanding. The calculation of air parcel trajectories as an integrated part of a kilometer-scale GPU-accelerated numerical model simulation not only exploits the full model time step, which leads to a significant increase in accuracy, but also avoids the need to store large amounts of four-dimensional data at high spatio-temporal resolution. Such online air parcel trajectories are an important prerequisite to enable Lagrangian studies of the atmospheric circulation on climate time scales.
The numerical weather prediction model COSMO was one of the first that gained both the ability to compute online air parcel trajectories (Miltenberger et al., 2013) and to run on GPU accelerators (Fuhrer et al., 2014; Lapillonne and Fuhrer, 2014), but both developments occurred independently of each other. In order to unite them, the mixed IAC/C2SM team participated in the CSCS GPU Hackathon with the goal of porting the online air parcel trajectory module to GPUs and optimizing it. There were several technical issues to be addressed during the Hackathon. First, because COSMO is parallelized using a checkerboard approach, the computational domain is decomposed between different compute nodes that exchange information using the MPI paradigm. Each compute node locally solves the model equations on its small part of the domain and exchanges necessary information with neighboring nodes via a halo in a structured and predictable way. By contrast, air parcel trajectories are not restricted to the grid but move freely through the three-dimensional model space. They travel between nodes and are often distributed unevenly across the domain, which impedes efficient parallelization. Additionally, their location between grid points necessitates repeated interpolation steps. The gained technical knowledge derived from resolving these issues will prove valuable once the GPU-accelerated ICON replaces COSMO.
This year, the CSCS GPU Hackathon was carried out completely online for the first time. It featured daily progress reports in Zoom community presentations, as well as live Q&A sessions with experts on NVIDIA debuggers and profilers and even recreational Tai chi breaks. Programming work was carried out in small breakout teams live via Zoom with screen-shared terminals, code was exchanged via Github and Slack was used for all written communication, including with the mentors, the CSCS cluster support and PGI experts. Code preparation was key to success. During the week before the main event, the team (with enthusiastic support by their mentors) prepared a standalone version of the COSMO online trajectory module that allowed for fast and focused development, debugging and optimization.
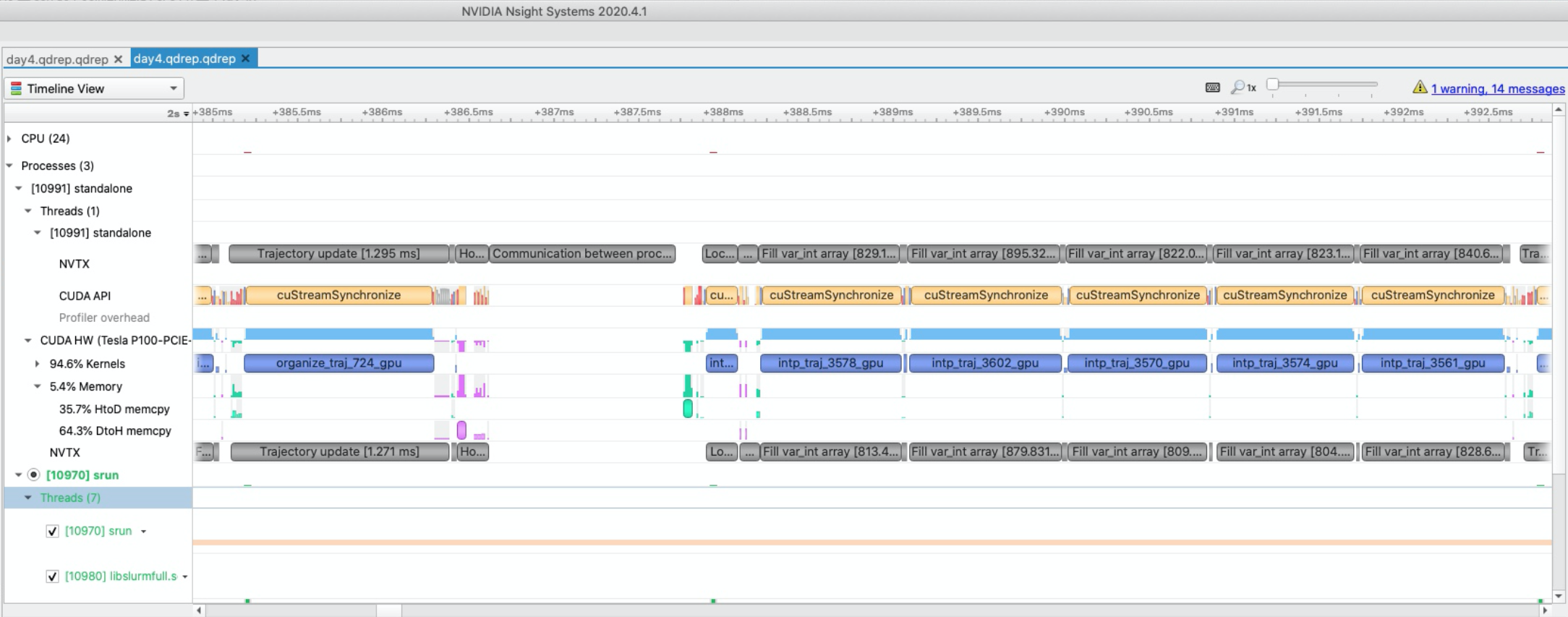
One of the most important daily steps was profiling the original code with NVIDIA NSight, which creates detailed timings of code running on
GPUs down to the level of individual loops and data transfers. An example of NSight is shown in Figure 2, alongside a loop that has to be rewritten to be parallelized. Using NSight, the team was able to pinpoint the most time-consuming part of the code, the air parcel location interpolation, and target this routine for optimization. The profiling of the code also greatly simplified the identification of unnecessary data movements between the CPU and the GPU. Substantial speedup could be achieved by using the OpenACC directive “!$acc host_data use_device” to run MPI calls with GPU data and thereby eliminate costly data transfers. Non-trivial problems occurred repeatedly, among them compiler errors. A final major bottleneck in the interpolation routine proved to be an inherently sequential loop, which was finally removed by simply executing it on the CPU because the memory transfers took much less time than the launch and sequential execution of a GPU kernel. By the end of the event, the online air parcel trajectory computational time step was reduced from 217 ms to 7.5 ms, a huge step forward.
The GPU Hackathon was a great experience. Debuggers like DDT and profilers like Nvidia NSight are powerful and extremely helpful for code optimization on large, heterogeneous high-performance computer architectures. Nevertheless, debugging code in a mixed CPU-GPU environment remains very time consuming, and sometimes simple print debugging is faster than getting a sophisticated tool to run. The
newly GPU-accelerated online air parcel trajectory module is currently being reintegrated into the full COSMO model. We are looking forward to study phenomena like cloud-circulation interactions at an unprecedented level of detail using large-scale convection-resolving simulations, and in the near future to integrating the module also in the ICON model.
The team:
Dr. Katie Osterried (C2SM), Dr. Stefan Rüdisühli and Prof. Dr. Sebastian Schemm (Atmospheric Circulation), Lukas Jansing and Dr.Michael Sprenger (Atmospheric Dynamics). Supported by their mentors Luca Ferraro (CINECA, Rome) and Lukas Mosimann (NVIDIA, Zurich), a former IAC master student.
References:
Fuhrer, O., Osuna, C., Lapillonne, X., Gysi, T., Cumming, B., Bianco, M., Arteaga, A., and Schulthess, T.: Towards a performance portable, architecture agnostic implementation strategy for weather and climate models, Supercomput. Front. Innov., 1, 45–62, external page https://doi.org/10.14529/jsfi140103, 2014.
Lapillonne, X. and Fuhrer, O.: Using compiler directives to port large scientific applications to GPUs: An example From atmospheric science, Parallel Process .Lett., 24, external page https://doi.org/10.1142/S0129626414500030, 2014.
Miltenberger, A. K., Pfahl, S., and Wernli, H.: An online trajectory module (version 1.0) for the nonhydrostatic numerical weather prediction model COSMO, Geosci. Model Dev., 6, 1989–2004, external page https://doi.org/10.5194/gmd-6-1989-2013, 2013.